AudioGuide1.72 Manual
By Ben Hackbarth, Norbert Schnell, Philippe Esling, Diemo Schwarz, Gilbert Nouno.Copyright Ben Hackbarth, 2011-2020.
Installation
For the moment AudioGuide1.72 only works on OS X. On more current versions of OS X it should run out of the box with python2 or python3. Here is a complete list of the resources that AudioGuide1.72 requires on your computer:- numpy (python >= 2.7 has numpy pre-installed I think) - Numpy is a numerical computation plugin for Python. Upgrading to the latest python2.7 should automatically install numpy. If you don’t have it, you can download the source code or a binary installer here. Or run "sudo easy_install pip" then "python -m pip install numpy"
- csound6 - Needed if you would like AudioGuide to automatically render concatenations (which you probably do). Download an installer from here.
Quick Start
We are going to do concatenative synthesis with an excerpt of speech as the target and some music by Helmut Lachenmann as the corpus. First we need to break the lachenmann soundfile into small chunks, called segments, which will populate our corpus. Do this by using the agSegmentSf.py script and running the following command in the terminal:python agSegmentSf.py examples/lachenmann.aiff
python agConcatenate.py examples/01-simplest.py
The reason that segmentation and concatenation are separated into discrete steps that I find is useful to fine-tune the segmentation of corpus sounds before using them in a concatenation. Soundfile segmentation is a difficult technical problem and should remain conceptually and aesthetically open-ended. I have yet to find an algorithm that does not require adjustments based on the nature of the sound in question and the intention of the user as to what a segment should be.
Corpus Segmentation
There are several tools in AudioGuide1.72 to segment long soundfiles into smaller chucks for use in concatenation. The sections below detail two such scripts, agSegmentSf.py and agGranulateSf.py. agSegmentSf.py segments soundfiles into chunks based on the rise and fall of the file's amplitude; agGranulateSf.py makes overlapping grains suitabile for traditional granular synthesis. Keep in mind that you do not need to use AudioGuide scripts if you do not want to -- alternatively you can:- Use whole soundfiles as corpus segments. If you only want to use folders of sounds that have been pre-segmented into individual files, you can skip this section and proceed to the concatenation section (However make sure tell AudioGuide not to search for segmentation textfiles by setting the corpus attribute wholeFile=True. See Manipulating How Directories Are Read for more info.).
- Create segmentation files by hand. You can do this in Audacity with its 'Labels' feature. Create a label track and indicate the start and end times of desired sound segments. Then "Export Labels..." and give the outputfile the same name as the soundfile + '.txt'. So, 'examples/lachenmann.aiff' would need a label file named 'examples/lachenmann.aiff.txt'.
- Create segmentation files with other software as long the textfile is written in the same format as AudioGuide’s.
Corpus Segmentation with agSegmentSf.py
The script you use to segment your corpus files according to it's acoustic features is called ‘agSegmentSf.py’. AgSegmentSf.py creates textfiles which denote the start and stop times of sound segments in a multi-segment audiofile. To segment a corpus file, ‘cd’ into the AudioGuide1.72 folder and run the following command:python agSegmentSf.py examples/lachenmann.aiff
---------------------- AUDIOGUIDE SEGMENT SOUNDFILE ----------------------
Evaluating /Users/ben/Documents/AudioGuide1.72/examples/lachenmann.aiff from 0.00-64.65
AN ONSET HAPPENS when
The amplitude crosses the Relative Onset Trigger Threshold: -40.00 (-t option)
AN OFFSET HAPPENS when
1. Offset Rise Ratio: when next-frame’s-amplitude/this-frame’s-amplitude >= 1.30 (-r option)
...or...
2. Offset dB above minimum: when this frame’s absolute amplitude <= -80.00 (minimum found amplitude of -260.00 plus the offset dB boost of 12.00 (-d option))
Found 144 segments
Wrote file /Users/ben/Documents/AudioGuide1.72/examples/lachenmann.aiff.txt
Finessing Corpus Segmentation
The script ‘agSegmentSf.py’ gives several options in the form of command line flags for setting different parameters that affect how soundfiles are segmented. You can read about them by typing ‘python agSegmentSf.py -h’. Segment onsets are determined by the -t flag. Offsets are determined by a combination of the -d, -a, and -r flags. Segmenation multirise can be turned on with the addition of the -m flag. These flags are detailed below.- -t <value> (between -200 and -0; the default is -40) - This flag gives the onset trigger threshold value in dB. When the soundfile's amplitude rises above the threshold, a segment onset is created. Higher values closer to 0 will lead to fewer onsets.
- -d <value> (between 0 and 100; the default is +12) - This flag sets the relative offset trigger threshold. This value is added to the soundfile’s minimum amplitude. During segmentation, if a frame’s amplitude is below this threshold, it causes a segment offset. FOr instance, if the lowest amplitude in the soundfile is -82 and -d is set to +12, a dB value of -70 dB will cause a segment offset. Also see -a.
- -a <value> (between -200 and -0; the default is -80) - This flag changes the segmentation offset absolute threshold. When segmenting the target, if a frame's amplitude is below this value it will cause an offset. This variable is an absolute value whereas -d specifies a value relative to the soundfile’s minimum amplitude. Effectively, whichever of these two variables is higher will be the offset threshold. Also seer -d.
- -r <value> (greater than 1; the default is 1.1) - This flag gives the offset rise ratio. It causes an offset when the ampltiude of the soundfile in the next frame divded by the amplitude of the current frame is greater than or equal to this ratio. Therefore if you are in a current sound segment, but the soundfile suddenly gets much louder, the current segment ends.
- -m - When this flag is present it turns on the segmentation multirise feature. Essentially this creates a larger number of corpus segments which can overlap each other. When this flag is present the segmentation algorithm will loop over the corpus soundfile several times, varying the user supplied riseRatio (-r) +/- 20%. This leads to certain segments will start at the same time, but last different durations. Try 'agSegmentSf.py examples/lachenmann.aiff' with and without the -m flag and look at the difference when importing examples/lachenmann.aiff.txt in Audacity.
python agSegmentSf.py -t -30 -d 4 soundfilename.wav # sets the threshold to -30. it will produce less onsets then -40 (the default). also changes the drop dB value to 4 dB above the minimum amplitude found in the entire soundfile, likely leading to longer segments.
python agSegmentSf.py -r 4 soundfilename.wav # changes the rise ratio from the default (1.1) to 4. This means that a frame's amplitude must be four times louder than the previous one to start a new segment
python agSegmentSf.py mydir/*.aiff # create a segmentation file for each aiff file located in mydir/
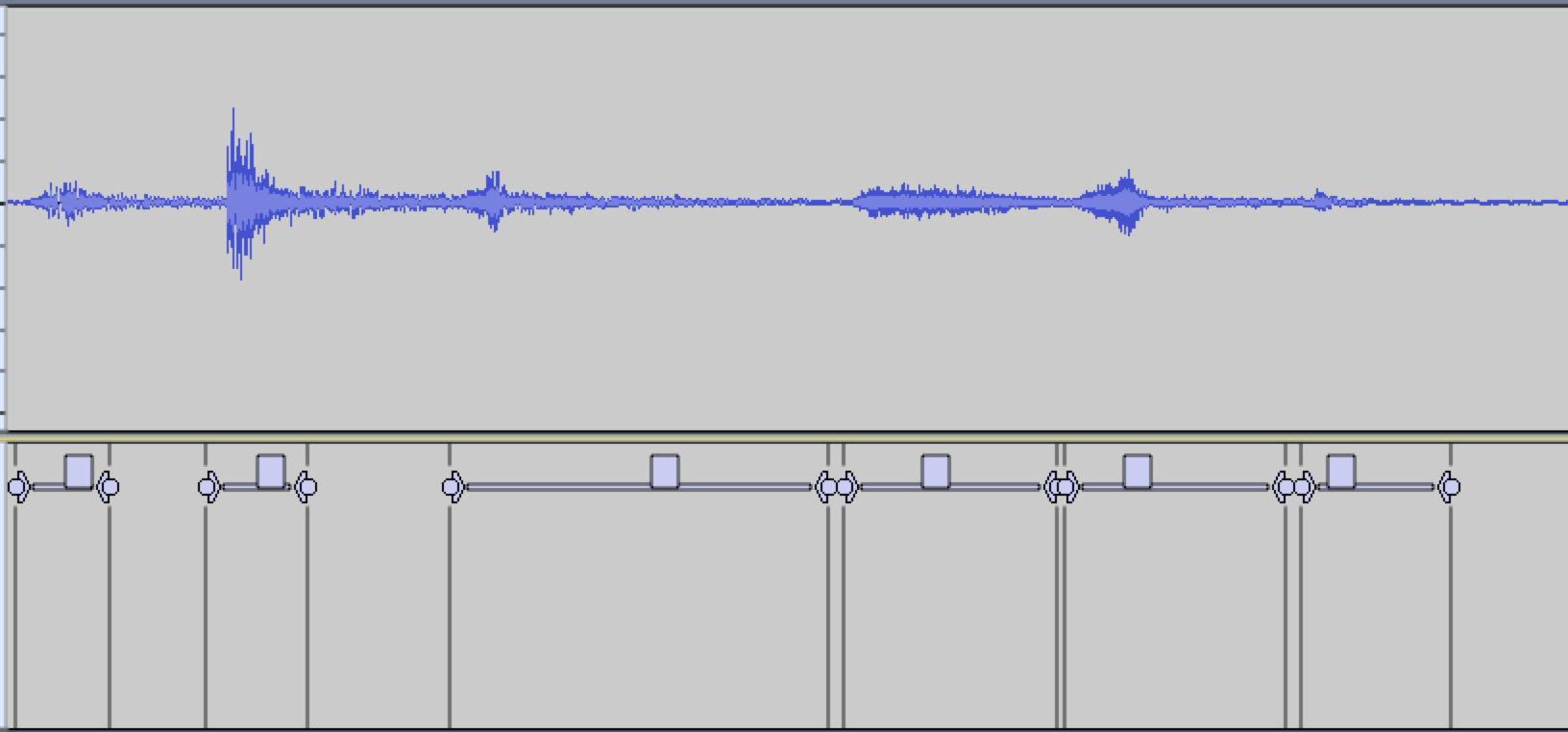
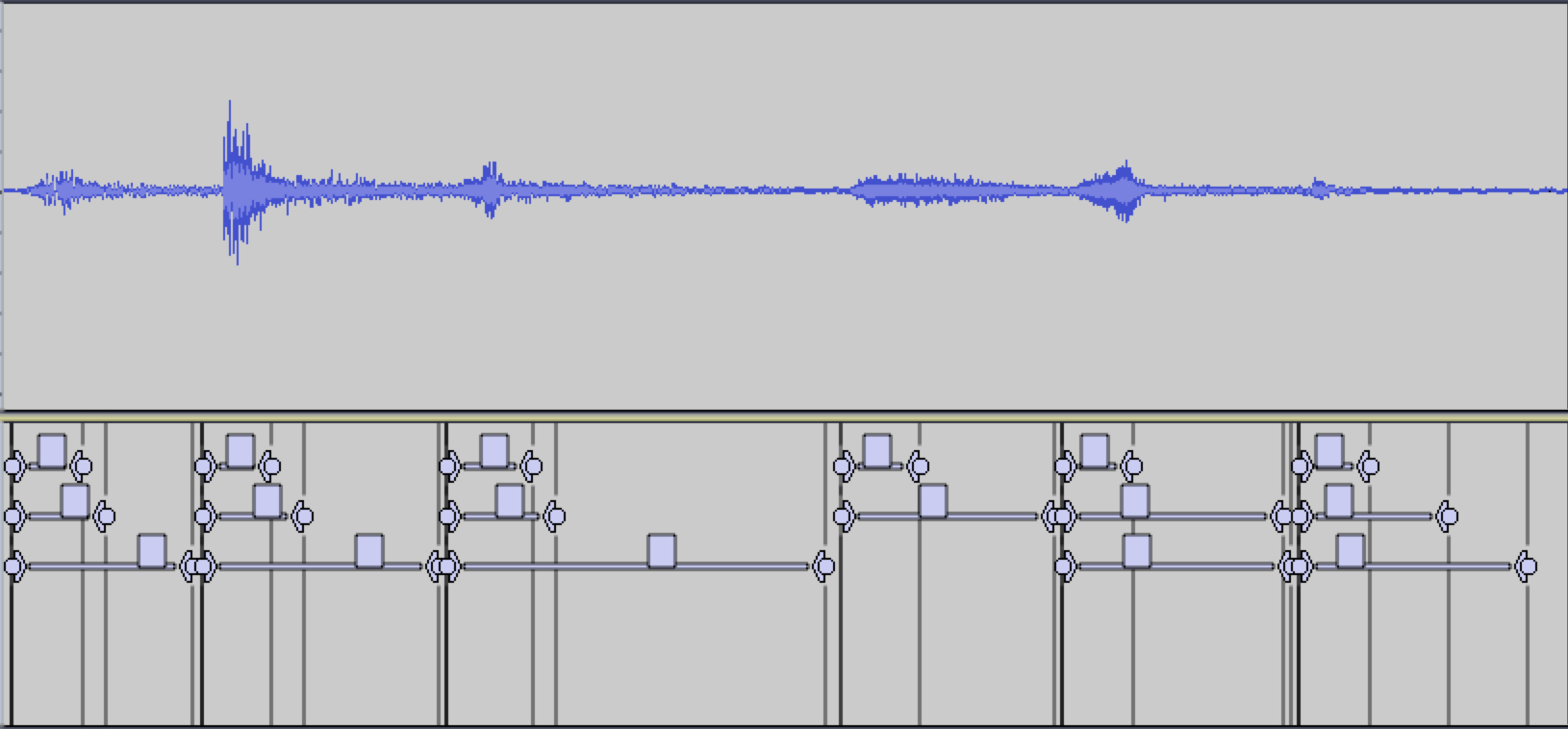
Corpus Segmentation with agGranulateSf.py
A script you can use to segment your corpus files for use with granular synthesis is called ‘agGranulateSf.py’. Like agSegmentSf.py, agGranulateSf.py creates textfiles which denote the start and stop times of sound segments in a multi-segment audiofile. Unlike agSegmentSf.py, this script chops up a soundfile into evenly size grains and provides a mechanism for adjusting grain overlap. To segment a corpus file, ‘cd’ into the AudioGuide1.72 folder and run the following command:python agGranulateSf.py examples/lachenmann.aiff
- -g <value> (greater than zero; the default is 0.1) - This flag sets the length of generated grains in seconds. Target and Corpus generated with agGranulate will be this length.
- -o <value> (greater than zero, less than -g; the default is 0.05) - This flag sets the distance between sucessive grain overlaps in seconds. If this value is 0.05 a new grain will begin every 0.05 seconds. If -g is 0.3, the overlap of grains will be 6.
- -t <value> (between -200 and -0; the default is -40) - This flag gives the onset trigger threshold value in dB. When the soundfile's amplitude rises above the threshold, grains start being generated. Higher values closer to 0 will lead to fewer grains.
- -d <value> (between 0 and 100; the default is +12) - This flag sets the relative offset trigger threshold. This value is added to the soundfile’s minimum amplitude. During segmentation, if a frame’s amplitude is below this threshold, it causes grains to stop being generated. For instance, if the lowest amplitude in the soundfile is -82 and -d is set to +12, a dB value of -70 dB will cause grains to cease. Also see -a.
- -a <value> (between -200 and -0; the default is -80) - This flag changes the segmentation offset absolute threshold. When segmenting the target, if a frame's amplitude is below this value it will cause grains to stop being generated. This variable is an absolute value whereas -d specifies a value relative to the soundfile’s minimum amplitude. Effectively, whichever of these two variables is higher will be the offset threshold. Also see -d.
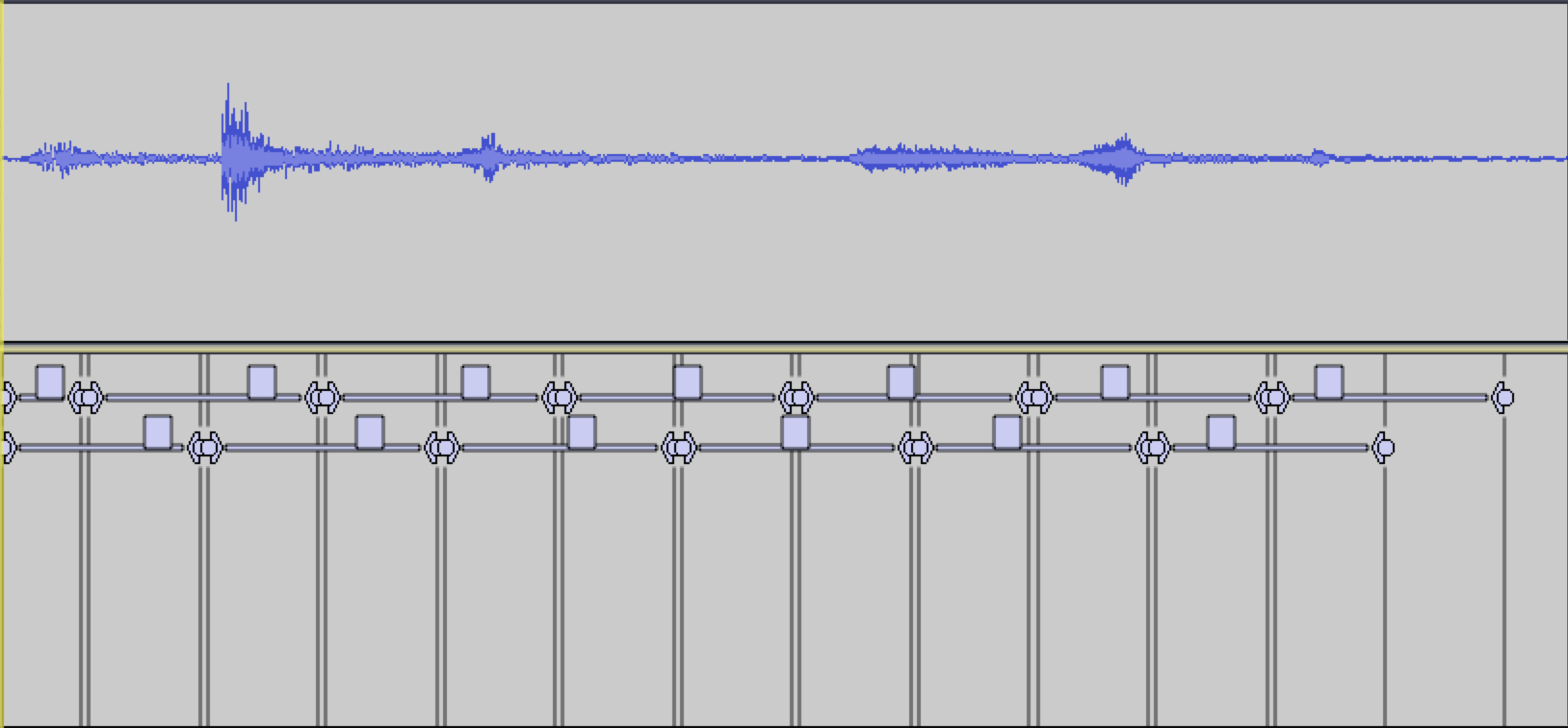
csf('lachenmann.aiff', onsetLen='50%', offsetLen='50%')
Concatenating with agConcatenate.py
Once you have segmented corpus soundfiles to your satisfaction, you are ready to call the concatenation script agConcatenate.py with a special AudioGuide1.72 options file as the first (and only) argument.To run one of the examples in the examples directory, run the following command inside the AudioGuide1.72 directory:
python agConcatenate.py examples/01-simplest.py
- Run an ircamdescriptor analysis of the soundfile in the TARGET variable (note: the analysis is only done once -- subsequent usages of this soundfile simply read data from disk. Analysis files are stored in a directory called ‘AudioGuide1.72/audioguide/data/’ in the AudioGuide1.72 folder. This directory can become quite large since these files are quite substantial in size. Removing this folder will cause all analysis files to be recomputed).
- Segment the target sound according to your options file. An Audacity-style label file is created in a file called ‘output/tgtlabels.txt’ in the output directory.
- Run an ircamdescriptor analysis of the soundfiles in the CORPUS variable (only the first time each of these files are used).
- (If you’ve specified them) Remove corpus segments according to descriptor limitations (Nothing above a certain pitch, nothing below a certain dynamic, etc.).
- Normalize target and corpus descriptor data according to your options file (see this discussion and the "norm" and "normmethod" in the section Descriptors and the d() object).
- Go through each target segment one by one. Select corpus segment(s) to match each target segment according to the normalized descriptors and search passes in the SEARCH variable (see the section SEARCH variable and spass() object) of your options file. Control over the layering and superimposition of corpus sounds is specified in the SUPERIMPOSE variable (see the section The SUPERIMPOSE variable and si() object).
- Write selected segments to a csound score called ‘output/output.csd’. (In addition to the csd file there are many other types of outputs (see the section Concatenation Output Files).
- If you have csound, ‘output/output.csd’ is rendered with csound to create an audiofile called ‘output/output.aiff’.
- If you have csound, automatic playback of ‘output/output.aiff’ at the command line.
CSOUND_RENDER_FILEPATH = '/path/to/the/file/i/want.aiff' # sets the path of the csound output aiff file
DESCRIPTOR_HOP_SIZE_SEC = 0.02049 # change the analysis hop size
Running agConcatenate.py in Interactive Mode
-> Watch a related discussion from the AudioGuide Tutorial.
As of version 1.6, agConcatenate.py can be run in "interactive mode" by adding the -i flag at runtime. The interactive mode runs agConcatenate.py as normal except that, after rendering and playing the concatenated output, the program stays open and monitors the loaded options file for changes. When the options file is modified and saved, agConcatenate.py will examine the changes and only rerun the parts of the program needed to create a new output. This makes auditioning->tweaking->auditioning the same options file much faster, especially when working with large corpi.
To run agConcatenate.py in interactive mode, add the -i flag:python agConcatenate.py examples/01-simplest.py -i
To exit interactive mode, type control-C.
The TARGET Variable and tsf() object
The TARGET variable is written as a tsf() object which requires a path to a soundfile and also takes the following optional keyword arguments:tsf('pathtosoundfile', start=0, end=file-length, thresh=-40, offsetRise=1.5, offsetThreshAdd=+12, offsetThreshAbs=-80, scaleDb=0, minSegLen=0.05, maxSegLen=1000, midiPitchMethod='composite', stretch=1, segmentationFilepath=None)
- start - The time in seconds to start reading the soundfile.
- end - The time in seconds to stop reading the soundfile.
- thresh - Segmentation onset threshold: a value from -100 to 0. This is equilavent to the function of the -t flag.
- offsetRise - Segmentation offset ratio: a number greater than 1. This is equilavent to the function of the -r flag.
- offsetThreshAdd - Segmentation offset relative threshold: a positive value in dB. This is equilavent to the function of the -a flag.
- offsetThreshAbs - Segmentation offset absolute threshold: a negative value in dB. This is equilavent to the function of the -d flag.
- minSegLen - Segmentation: the minimum duration in seconds of a target segment.
- maxSegLen - Segmentation: the maximum duration in seconds of a target segment.
- scaleDb - Applies an amplitude change to the whole target sound. By default, it is 0, yielding no change. -6 = twice as soft. The target’s amplitude will usually affect concatenation: the louder the target, the more corpus sounds can be composited to approximate it’s energy profile.
- midiPitchMethod - same as corpus method documented here.
- segmentationFilepath - by default the Target sound is segmented at runtime. However, if you’d like to specify a user-defined segmentation, you may give a file path to this variable. Note that this file must be a textfile with the same format as corpus segmentation files.
TARGET = tsf('cage.aiff') # uses the whole soundfile at its given amplitude
TARGET = tsf('cage.aiff', start=5, end=7, scaleDb=6) # only use seconds 5-7 of cage.aiff at double the amplitude.
The CORPUS Variable and csf() object
-> Watch a related discussion from the AudioGuide Tutorial.
The CORPUS variable is defined as a list of csf() objects which require a path to a soundfile OR a directory. File paths and/or directory paths may be full paths or relative paths to the location of the options file you’re using or a path found in the SEARCH_PATHS variable. A csf() object required the soundfile/directory name, then takes the following optional keyword arguments:csf('pathToFileOrDirectoryOfFiles', start=None, end=None, includeTimes=[], excludeTimes=[], pitchfilter={}, limit=[], wholeFile=False, recursive=True, includeStr=None, excludeStr=None, scaleDb=0.0, limitDur=None, clipDurationToTarget=False, onsetLen=0.01, offsetLen='30%', midiPitchMethod='composite', transMethod=None, transQuantize=0, concatFileName=None, allowRepetition=True, restrictRepetition=0.5, restrictOverlaps=None, restrictInTime=0, maxPercentTargetSegments=None, scaleDistance=1, superimposeRule=None, segmentationFile=None, segmentationExtension='.txt')
CORPUS = [csf("lachenmann.aiff")]# will search for a segmentation file called lachenmann.aiff.txt and add all of its segments to the corpus
CORPUS = [csf("lachenmann.aiff"), csf('piano')]# will use segments from lachenmann.aiff as well as all sounds in the directory called piano
CORPUS = [csf([['myfile1.wav', 14.5, 15.3], ['myfile1.wav', 103.7, 104.1], ['myfile2.wav', 0, None]])] # will use two segments from myfile1.wav and then entire file myfile2.wav as the corpus
Note: Each of these keyword arguments only apply to the csf() object within which they are written. If you’d like to specify these parameters for the entire corpus, see Specifying csf() keywords globally.
Which Segments are Added to the Corpus
Below are csf() keywords which influence which sound segments make it into the corpus.- start - Any segments which start before this time will be ignored.
- end - Any segments which start after this time will be ignored.
csf('lachenmann.aiff', start=20) # only use segments that start later than 20s. csf('lachenmann.aiff', start=20, end=50) # only use segments that start between 20-50s. - includeTimes - A list of two-number lists which specify regions of segments to include from this file’s list of segment times. See example below.
- excludeTimes - Same as includeTimes but excludes segments in the identified regions.
csf('lachenmann.aiff', includeTimes=[(1, 4), (10, 12)]) # only use segments falling between 1-4 seconds and 10-12 seconds. csf('lachenmann.aiff', excludeTimes=[(30, 55)]) # use Target and Corpus except those falling between 30-55s. - limit - A list of equation-like strings where segmented descriptor names are used to include/exclude segments from this file / directory.
csf('lachenmann.aiff', limit=['centroid-seg >= 1000']) # segments whose centroid-seg is equal to or above 1000. csf('lachenmann.aiff', limit=['centroid-seg < 50%']) # only use 50% of segments with the lowest centroid-seg. csf('lachenmann.aiff', limit=['power-seg < 50%', 'power-seg > 10%']) # only use segments whose power-seg falls between 10%-50% of the total range of power-seg's in this file/directory. - pitchfilter - removes segments from a csf() entry based on whether or not each segment matches midipitches specified by the user. The user supplies a dictionary with a list of pitches. pitches less than 12 will be treated as pitch classes, i.e. if 0 is given, all pitches modulo 12 which equal 0 will be included. Corpus segments' pitches may be transposed to fit the given pitches -- the 'tolerance' key specifies a semitone tranposition tolerance. For instance, pitchfilter={'pitches': [60], 'tolerance': 3} will include Target and Corpus whose pitch is +-3 semitones from 60, and audioguide will transpose these pitches to be played back at the neaest pitch found in pitches, in this case 60. Note that this feature will override any other transposition given in csf(transMethod=). Also note that a corpus segment's pitch is determined with the segment's MIDIPitch-seg, which can be controled according to csf(midiPitchMethod=)
csf('pianosamples', pitchfilter={'pitches': [60, 68, 73]}), # discard any segments that do not match any of the given midipitches csf('pianosamples', pitchfilter={'pitches': [60, 68, 73], 'tolerance': 3}), # discard any segments that do not match any of the given pitches +-3 semitones csf('pianosamples', pitchfilter={'pitches': ['C4', 'Gs4', 'Db5'], 'tolerance': 3}), # you can also use strings with pitchnames! csf('pianosamples', pitchfilter={'pitches': [1, 'E4'], 'tolerance': 3}), # C sharp in any octave and E4 will make it through! - segmentationFile - Manually specify the segmentation text file. By default, AudioGuide automatically looks for a file with the same name as the soundfile plus the extension ‘.txt’. You may specify a path file (as a string), or a list of strings to include multiple segmentation files which all use the same soundfile.
- segmentationExtension - Manually specify the segmentation text file extension. See above.
csf('lachenmann.aiff', segmentationFile='marmotTent.txt') # will use a segmentation file called marmotTent.txt, not the default lachenmann.aiff.txt.
csf('lachenmann.aiff', segmentationExtension='-gran.txt') # will use a segmentation file called lachenmann.aiff-gran.txt, not the default lachenmann.aiff.txt.
How Directories Are Read
The following csf() keyword arguments are useful when dealing with directories of files.- wholeFile - if True AudioGuide will use this soundfile as one single segment. If False, AudioGuide will search for a segmnetation file made with agSegmentSf.py.
csf('sliced/my-directory', wholeFile=True) # will not search for a segmentation txt file, but use whole soundfiles as single segments. - recursive - if True AudioGuide will include sounds in all subfolders of a given directory.
csf('/Users/ben/gravillons', wholeFile=True, recursive=False) # will only use soundfiles in the named folder, ignoring its subdirectories. - includeStr - A string which is matched against the filename (not full path) of each soundfile in a given directory. If part of the soundfile name matches this string, it is included. If not it is excluded. This is case sensitive. See example below.
- excludeStr - Opposite of includeStr.
# includeStr/excludeStr have lots of uses. One to highlight here: working with sample databases which are normalized. Rather than having each corpus segment be at 0dbs, we apply a scaleDb value based on the presence of a ‘dynamic' written into the filename. csf('Vienna-harpNotes/', includeStr=['_f_', '_ff_'], scaleDb=-6), csf('Vienna-harpNotes/', includeStr='_mf_', scaleDb=-18), csf('Vienna-harpNotes/', includeStr='_p_', scaleDb=-30), # this will use all sounds from this folder which match one of the three dynamics; also see scaleDb='filenamedyn', below.
How Segments Will Be Concatenated
Below are csf() keywords which influence how sound segments are treated during concatenation.- scaleDb - applies an amplitude change to each segment of this collection. by default, it is 0, yielding no change. -6 = twice as soft. Note that amplitude scaling affects both the concatenative algorithm and the csound rendering. Also note that scaleDb='filenamedyn' will attempt to scale all sounds in this corpus by finding a dynamic written in the filenames according to DYNAMIC_TO_DECIBEL and FILENAMESTRING_TO_DYNAMICS.
- limitDur - limits the duration of each segment from this csf() entry. The duration of Target and Corpus over this value (in seconds) will be truncated. This happens before concatenation.
- clipDurationToTarget - If True, the duration of any selected sounds from this csf() will be truncated by the duration of the target. This happens after concatenation takes place.
- onsetLen - if onsetLen is a float or integer, it is the fade-in time in seconds. If it is a string formed as ’10%’, it is interpreted as a percent of each segment’s duration. So, onsetLen=0.1 yields a 100 ms. attack envelope while onsetLen=’50%’ yields a fade in over 50% of the segment’s duration.
- offsetLen - Same as onsetLen, but for the envelope fade out.
csf('lachenmann.aiff', onsetLen=0.1, offsetLen='50%') # will apply a 100ms fade in time and a fade out time lasting 50% of each segments' duration. - midiPitchMethod - this tells AudioGuide how to calculate the descriptor d('MIDIPitch-seg') for each segment in a tsf() or csf() object. Note that this value is important for writing the bach output files, as it determines the displayed pitch of each target and corpus event. It is also important for csf(limit) and csf(pitchfilter). Note that if any of the methods, detailed below, do not find a result, -1 is returned.
- ‘f0-seg’ - returns the averaged f0 array as the midipitch. Note that it is not power weighted - it is actually the median of f0.
- ‘centroid-seg’ - returns the power averaged centroid converted into a midipitch.
- ‘filename’ - looks at the filename of the corpus segment to see if there is a midipitch indicated. Names like A1ShortSeq.wav, Fs1ShortSeq.wav and BP-flatter-f-A\#3.wav work.
- ‘composite’ - first tries to look for a midipitch in the filename. If not found, then tries ‘f0-seg’.
- float/int - a float or int will set all pitches in this csf() to the midipitch written.
- {'type': 'remap', 'low': 60, 'high': 72, 'method': 'centroid-seg'} - will first determine the pitches in this csf() based on centroid, then remap these values to be between 60 and 70.
- {'type': 'clip', 'low': 60, 'method': 'centroid-seg'} - will first determine the pitches in this csf() based on centroid, then force any pitch below 60 to be 60.
- {'type': 'file_match', 'II': 60, 'IV': 72} - will set the midipitch of any filenames that match 'II' to 60; any that match 'IV' are 72, and all other are determined with the midiPitchMethod composite.
- transMethod - A string indicating how to transpose segments chosen from this corpus entry. You may chose from:
- None - yields no transposition.
- ‘random n m’ - transposes this segment randomally between midipitch n and m.
- ‘f0’ - transposes a selected corpus segment to match the f0-seg of the corresponding target segment.
- ‘f0-chroma’ - transposes a selected corpus segment to match the f0-seg of the corresponding target segment modulo 12 (i.e., matching its chroma).
- transQuantize - Quantization interval for transposition of corpus sounds. 1 will quantize to semitones, 0.5 to quarter tones, 2 to whole tones, etc.
csf('piano/', transMethod='f0') # transpose corpus segments to match the target's f0. csf('piano/', transMethod='f0-chroma', transQuantize=0.5) # transpose corpus segments to match the target's f0 mod 12. Then quantize each resulting pitch to the newest quarter of tone. - concatFileName - A string indicating a different soundfile path to use when rending with csound. This means that the first argument of the cps() object is used for soundfile descirptor analysis, but the path found in concatFileName if the soundfile used in the concatenated result. By default, concatFileName is set to the same filename as the first argument of the cps().
csf('lachenmann-mono.aiff', concatFileName='lachenmann.stereo.aiff'), # runs the descriptor analysis on lachenmann-mono.aiff, but then uses the audio from lachenmann.stereo.aiff when rendering the csound output. - allowRepetition - If False, any of the segments from this corpus entry may only be picked one time. If True there is no restriction.
- restrictRepetition - A delay time in seconds where, once chosen, a segment from this corpus entry is invalid to be picked again. The default is 0.5, which the same corpus segment from being selected in quick succession.
csf('piano/', allowRepetition=False) # each individual segment found in this directory of files may only be deleted one time during concatenation. csf('piano/', restrictRepetition=2.5) # Each segment is invalid to be picked if it has already been selected in the last 2.5 seconds. - restrictOverlaps - An integer specifying how many overlapping samples from this collection may be chosen by the concatenative algorithm at any given moment. So, restrictOverlaps=2 only permits 2 overlapping voices at a time.
- restrictInTime - a time in seconds specifying how often a sample from this entry may be selected. -- for example restrictInTime=0.5 would permit segments from this collection to be select a maximum of once every 0.5 seconds.
- maxPercentTargetSegments - a float as a percentage value from 0-100. This number limits the number of target segments that this corpus entry may be selected. For example, a value of 50 means that this corpus entry is only valid for up to 50% of target segments; after this threshold has been crossed, further selections are not possible. None is the default, which has no effect.
- scaleDistance - Scale the resulting distance when executing a multidimensional search using on segments. scaleDistance=2 will make these sounds twice as ‘far’, and thus less likely to be selected by the search algorithm. scaleDistance=0.25 makes 4 times more likely to be picked.
- superimposeRule - This one is a little crazy. Basically, you can specify when this corpus’s segments can be chosen based on the number of simultaneously selected samples. You do this by writing a little equation as a 2-item list. superimposeRule=(‘==’, 0) says that this set of corpus segments may only be chosen is this is the first selection for this target segment (sim selection ‘0’). superimposeRule=(‘$>$’, 2) say this corpus’s segments are only valid to by picked if there are already more than 2 selections for this target segment. I know, right?
Specifying csf() Keywords Globally
csf() keywords may be specified globally using the variable CORPUS_GLOBAL_ATTRIBUTES. Note that they are specified in dictionary format rather than object/keyword format.CORPUS = [csf('lachenmann.aiff', scaleDb=-6), csf('piano/', scaleDb=-6, wholeFile=True)]
# is equivalent to
CORPUS_GLOBAL_ATTRIBUTES = {'scaleDb': -6}
CORPUS = [csf('lachenmann.aiff'), csf('piano/', wholeFile=True)]
Normalization
-> Watch a related discussion from the AudioGuide Tutorial.
Target segments and corpus segments in AudioGuide are normalized with d() object keywords, documented in the section below.
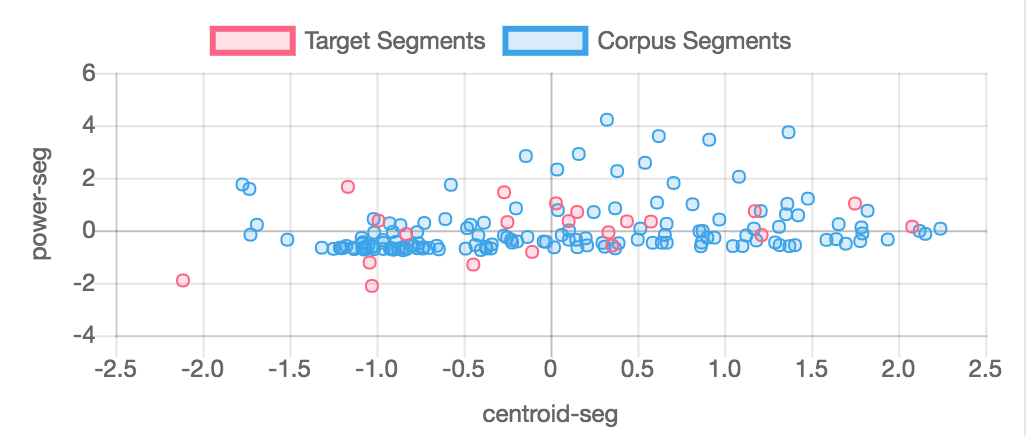
Normalization is important when measuring the similarity between two different data sets (target sound segments and corpus sound segments) - it is essentially a way of mapping the two data sets onto each other. It is often the case that the target soundfile is less "expressive" than the corpus - i.e. that the variation in the target sound's descriptors are less robust that the variation of the descriptors found across the corpus.This is the case in examples/01-simplest.py: Cage's voice is fairly monolithic with regard to timbre, amplitude, pitch, etc., which the Lachenmann contains a great deal more nuance in timbre and dynamics. Under these circumstances, what do we want AudioGuide to do? Should Cage's relatively small variation in descriptor space be matched to a relatively small subset of the corpus? Or should Cage's variation in descriptor space be streched to fit the total variation of the corpus? My default answer to this question (aesthetically, compositionally, musically) is the latter. And it is for that reason that AudioGuide's default mode of operating is to normalize target and corpus descirptor spaces separately so that the variability of the target is stretched to fit the variabley of the corpus.
This is done with the norm=2 flag in the d() object (norm=2 is the default value for the d() object); norm=1 normalizes the target and corpus descirptor spaces together so that descriptor values are better preserved. The two charts below show target and corpus segments from examples/01-simplest.py normalized together and separately to show the difference. Normalized descriptor values affect how similarity is measured and therefore which corpus segments will be picked to "match" target segments.
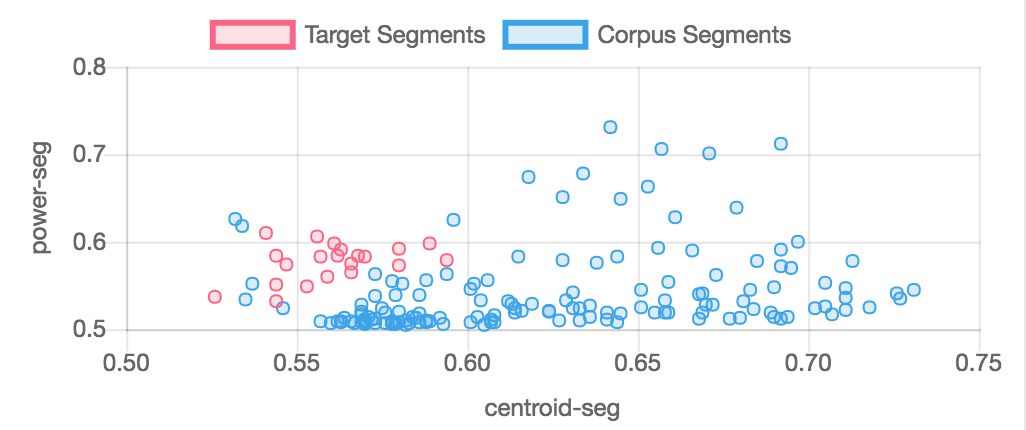
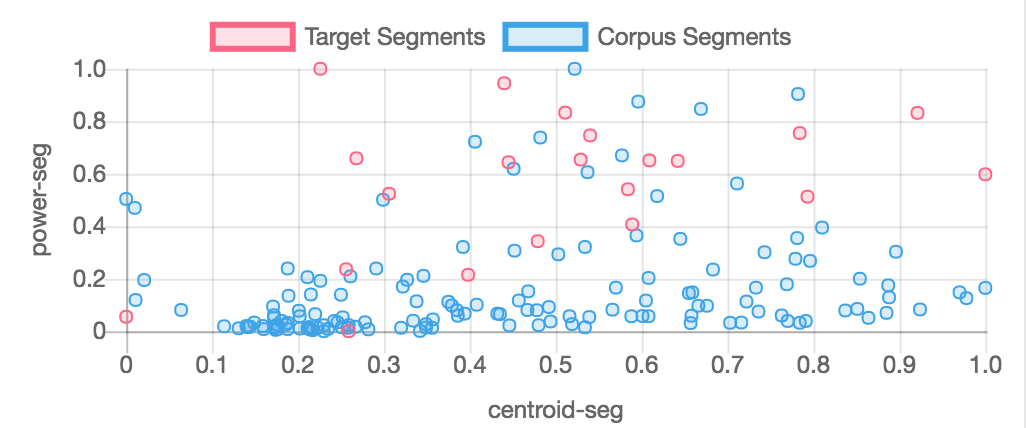
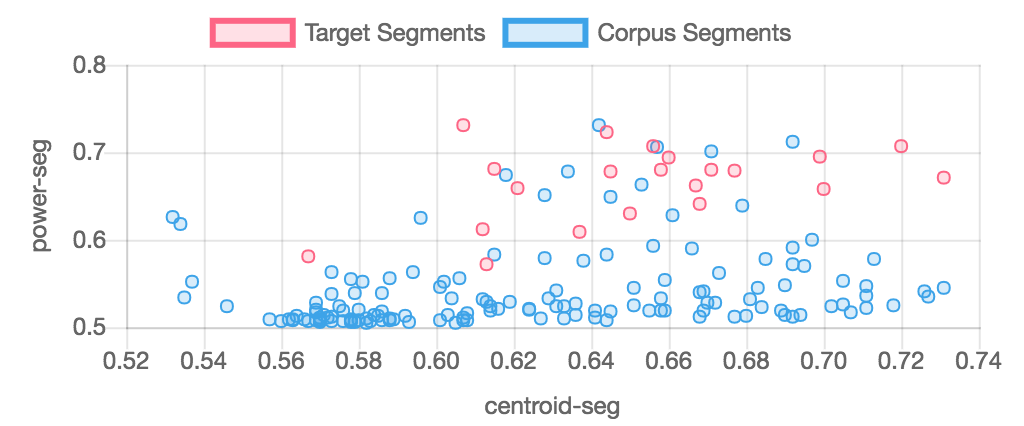
Descriptors and the d() object
-> Watch a related discussion from the AudioGuide Tutorial.
Use the d() object to specify a descriptor, how it is weighted, and how it is normalized. The d() object takes 1 argument -- the name of the desired descriptor -- and then several optional keywords arguments, detailed below.d('descriptor name', weight=1, norm=2, normmethod='stddev', distance='euclidean', energyWeight=False)
- descriptor name - a string of the name of the desired descriptor. Note that most (but not all) descriptors have both a time varying version as well as a power-weighted averaged version (‘-seg’). All possible descriptors are listed in Appendix 1.
- weight - How to weight this descriptor in relation to other descriptors.
SEARCH= [spass('closest', d('centroid', weight=1), d('noisiness', weight=0.5))]# centroid is twice as important as noisiness. - norm - A value of 2 normalizes the target and corpus data separately. A value of 1 normalizes the target and corpus data together. 2 will yield a better rendering of the target’s morphological contour. 1 will remain more faithful to concrete descriptor values. I recommend using 2 by default, only using 1 when dealing with very ‘descriptive’ descriptors like duration or pitch.
SEARCH = [spass('closest', d('centroid'), d('effDur-seg', norm=1))] - normmethod - How to normalize data -- either ‘stddev’ or ‘minmax’. minmax is more precise, stddev is more forgiving of ‘outliers.’
- distance - Only valid for time-varying descriptors. How to arithmetically measure distance between target and corpus arrays.
- ‘euclidean’ - does a simple least squares distance.
- ‘pearson’ - a pearson correlation measurement.
- ‘dtw’ - distance measurement according to dynamic time warping.
SEARCH = [spass('closest', d('centroid', distance='pearson'))] # uses a pearson correlation formula for determining distance between target and corpus centroid arrays. - energyWeight - Only valid for time-varying descriptors. Weight distance calculations with the corpus segments’ energy values. The means that softer frames will not affect distance as much as louder frames. Only works if distance=‘euclidean’.
SEARCH variable and spass() object
-> Watch a related discussion from the AudioGuide Tutorial.
The SEARCH variable tells AudioGuide how to pick corpus segments to match target segments. The SEARCH variable is a list of spass() objects which is evaluated in order for each segment in the target soundfile. Multiple search operations are chained together -- the output of each spass() becomes the input of the following spass().
SEARCH = [
spass(...), # first spass. the input is all valid corpus samples
spass(...), # second spass. the input is the output from the previous spass
]
The idea here is make a very flexible searching method where the user can create multiple search passes based on different descriptor criteria. The first argument of spass(), its 'method', is a string which denotes the type of search - i.e. how target and corpus segments are compared. A summary of different methods are listed below:
- closest - picks the best matching corpus sound according to one of more descriptors.
- farthest - picks the worst matching corpus sound according to one of more descriptors.
- closest_percent - returns a percentage of the best matching corpus sounds according to one of more descriptors.
- farthest_percent - returns a percentage of the worst matching corpus sounds according to one of more descriptors.
- ratio_limit - returns any corpus sounds if, for a given descriptor, the ratio of the target segment/corpus segment falls within certain user specified limits.
- parser - Structured as an if-then-else, this method toggles between two different actions depending on a whether a taget segment's descriptor passes a test.
spass() objects with the method closest return the single best matching corpus sound according to a list descriptor objects. This spass() objects should only be used as the last (or only) item of the SEARCH list.
spass('closest', d('centroid')) # pick the best matching corpus sound according to time-varying centroids
spass('closest', d('centroid'), d('mfccs-seg'), d('zeroCross-delta')) # pick the best matching corpus sound according to the equally weighted distances of centroid, segments mffcs, and first order zeroCross.
spass() objects with the method closest_percent return a percentage of the best matching corpus samples based on a list of descriptors. The keyword 'percent' is required.
spass('closest_percent', d('power-seg'), d('effDur-seg', norm=1), percent=10) # let the best matching 10 percent of courpus sounds through this pass according to averaged power and effective duration.
Note that if 'closest_percent' is the last (or only) entry in the SEARCH list, the final segment is randomly chosen among remaining corpus sounds.
spass() objects with the method ratio_limit use a single segmented descriptor and divide the targe value by each corpus value. Only corpus samples whose ratio is within the specified limits (keywords minratio and maxratio) are allowed to pass. If either the upper or lower limit is omitted, is has no effect.
spass('ratio_limit', d('effDur-seg'), minratio=0.9, maxratio=1.1) # let through corpus sounds if the ratio of target duration/corpus duration is between 0.9 to 1.1.
Note that ratio_limit only works with one segmented descriptor. It uses unnormalized descriptor values so that, in the case of the above example, the ratio is obtained by dividing the target segment's effDur by the corpus segment's effDur.
The parser spass() method toggles between two different actions depending on a whether each taget segment passes a test. Each spass() has the following parameters:
spass('parser', test, submethod, ifTrue, ifFalse)
- test - a string which is a boolean test of a target segment's segmented descriptor. e.g. 'power-seg > 0.1'
- submethod - a string denoting the type of operation to perform - possibilities are closest, closest_percent, and corpus_select
- ifTrue - a list of items to perform if ‘test’ is True.
- ifFalse - a list of items to perform if ‘test’ is False.
The first two submethods behave exactly like those outlined above. For instance:
spass('parser', 'closest', 'effDur-seg > 0.4', [d('zeroCross')], [d('zeroCross-delta')]) # if a target segment is less than 0.4 second long, pick the best corpus sound according to zeroCrossings; otherwise pick the best sound according to the first order difference of zeroCrossings
spass('parser', 'f0-seg == 0', 'closest_percent', [d('f0')], [d('mfccs-seg')], percent=10) # if f0-seg equals 0, return the closest 10 percent of matches to f0; otherwise return the 10 percent best matches according to mfccs-seg
spass('parser', 'closest', 'noisiness-seg >= 50%', [d('mfccs-seg')], [d('f0')]) # if this target segment's noisiness is in the upper 50 percentile among all target segments, return the best matching corpus sound according to mfccs; other use f0.
The third method, corpus_select, uses the target descriptor test to determine which items of the CORPUS list are valid:
spass('parser', 'effDur-seg > 0.4', 'corpus_select', [0], [1, 2]) # if the effective duration is less that 0.4 seconds, use corpus samples from arguemnt 1 of the corpus list; otherwise used samples from argument 2 and 3.
Contextual Examples
Here is the most simple case of a SEARCH variable:
SEARCH = [spass('closest', d('centroid'))] # will search all corpus segments and select the one with the ‘closest' time varying centroid to the target segment.
You may list as many descriptors are you want. The selected sample will be an average of all descriptors listed.
SEARCH = [spass('closest', d('centroid'), d('effDur-seg'))] # will search all corpus segments and select the one with the ‘closest' centroid and effective duration compared to the target segment.
If you use ‘closest_percent’ as the one and only spass object in the SEARCH variable, AudioGuide will select a corpus segment randomly among the final candidates.
SEARCH = [spass('closest_percent', d('centroid'), percent=20)] # pick randomally between the top 20 percent best matches.
However, you can also 'chain' spass objects together, essentially constructing a hierarchical search algorithm. So, for example, take the following SEARCH variable with two separate phases:
SEARCH = [
spass('closest_percent', d('effDur-seg'), percent=20), # take the best 20% of matches from the corpus
spass('closest', d('mfccs')), # now find the best matching segment from the 20 percent that remains.
]
I use the above example a lot when using AudioGuide. It first matches effDur-seg, the effective duration of the target measured agains’t the effective duration of each corpus segment. It retains the 20% closest matches, and throws away the worst 80%. Then, with the remaining 20%, the timbre of the sounds are matched according to mfccs.
SEARCH = [
spass('ratio_limit', d('f0-seg'), minratio=0.943, maxratio=1.059),# only let through corpus samples that are within +/-1 semitone of the target segment's f0
spass('closest', d('mfccs')), # now find the best matching segment according to timbre
]
To help the user understand how different spasses are functioning, the log.html file, created by default, contains a table in the concatenation section which shows information about the size of the corpus through each spass for each target segement search. The following is the table created for examples/09-parseSearch.py. For each pass, the size of the corpus is shown before and after the spass() operation. When a 'parser' spass() is used, the result of the boolean test is shown as well.
| time x overlap | spass #1: closest_percent | spass #2: parser | spass #3: closest |
|---|---|---|---|
| 1.46x1 | 252 -> 50 | False 50 -> 10 | 10 -> 1 |
| 4.74x1 | 252 -> 50 | False 50 -> 10 | 10 -> 1 |
| 7.82x1 | 252 -> 50 | True 50 -> 10 | 10 -> 1 |
| 0.26x1 | 252 -> 50 | True 50 -> 10 | 10 -> 1 |
| 1.10x1 | 251 -> 50 | True 50 -> 10 | 10 -> 1 |
| 5.17x1 | 251 -> 50 | False 50 -> 10 | 10 -> 1 |
| 6.83x1 | 252 -> 50 | False 50 -> 10 | 10 -> 1 |
| 9.47x1 | 252 -> 50 | True 50 -> 10 | 10 -> 1 |
| 4.34x1 | 251 -> 50 | True 50 -> 10 | 10 -> 1 |
| 4.49x1 | 250 -> 50 | True 50 -> 10 | 10 -> 1 |
| 8.53x1 | 252 -> 50 | False 50 -> 10 | 10 -> 1 |
| 0.68x1 | 250 -> 50 | True 50 -> 10 | 10 -> 1 |
| 6.42x1 | 251 -> 50 | False 50 -> 10 | 10 -> 1 |
| 10.28x1 | 252 -> 50 | False 50 -> 10 | 10 -> 1 |
| 7.28x1 | 251 -> 50 | True 50 -> 10 | 10 -> 1 |
| 6.13x1 | 251 -> 50 | True 50 -> 10 | 10 -> 1 |
| 7.08x1 | 250 -> 50 | False 50 -> 10 | 10 -> 1 |
| 8.93x1 | 251 -> 50 | False 50 -> 10 | 10 -> 1 |
| 10.53x1 | 251 -> 50 | False 50 -> 10 | 10 -> 1 |
| 8.34x1 | 251 -> 50 | False 50 -> 10 | 10 -> 1 |
| 7.62x1 | 250 -> 50 | True 50 -> 10 | 10 -> 1 |
The SUPERIMPOSE variable and si() object
-> Watch a related discussion from the AudioGuide Tutorial.
Use the si() object for specifying how corpus segments may be superimposed during concatenation.- minSegment - The minimum number of corpus segments that must be chosen to match a target segment.
- maxSegment - The maximum number of corpus segments that must be chosen to match a target segment.
- minFrame - The minimum number of corpus segments that must be chosen to begin at any single moment in time.
- maxFrame - The maximum number of corpus segments that must be chosen to begin at any single moment in time.
- minOverlap - The minimum number of overlapping corpus segments at any single moment in time. Note that an ‘overlap’ is determined according to an amplitude threshold -- see overlapAmpThresh.
- maxOverlap - The maximum number of overlapping corpus segments at any single moment in time. Note that an ‘overlap’ is determined according to an amplitude threshold -- see overlapAmpThresh.
- searchOrder - (‘power’ or ‘time’) The default is ‘time’, which indicated to match corpus segments to target segments in the temporal order of the target (i.e., first searched segment is the first segment in time). ‘power’ indicates to first sort the target segments from loudest to softest, then search for corpus matches.
- calcMethod - A None/string which denotes how to audioguide should account for selected corpus sounds that overlap. By default, it is 'mixture'. Note that not all descriptors can be algorithnmically mixed, e.g. f0, zeroCross. More information in this tutorial video clip.
- None - No accounting for previously selected corpus sounds. Each selected sound is unaware of previous selections.
- ‘subtract’ - subtracts a selected corpus sound's amplitude from the target segment's amplitude.
- ‘mixture’ - performs 'subtract', then attempts to mix descriptors of previously selected corpus sound together inform the next corpus selection.
- subtractScale - A float/int/string which denotes how much of a corpus sound's amplitude to subtract from the target. By default it is 1; a value of 0.5 will scale corpus semgment amplitudes by 0,5 before subtracting them from the target. This variable is only meaningful if si(calcMethod='subtract') or si(calcMethod='mixture'). More information in this tutorial video clip.
- float/int - Scale the amplitude of corpus sounds by this number when subtracting them from the target.
- ‘automedian’ - use the median of target and corpus segment amplitudes to determine the amount to scale subtraction.
- ‘automax’ - use the maximum of target and corpus segment amplitudes to determine the amount to scale subtraction.
Concatenation Output Files
For each of the following _FILEPATH variables, a value of None tells the agConcatenate.py NOT to create an output file. Otherwise a string tells agConcatenate.py to create this output file and also indicates the path of the file to create. Strings may be absolute paths. If a relative path is given, AudioGuide will create the file relative to the location of the agConcatenate.py script.
Pro tip: You can also use the special string '$TIME' in any output file path to automatically insert the current time stamp into output filenames. This keeps audioguide from overwriting files from previous agConcatenate.py runs. See examples/07-outputfiles.py for details.
CSOUND_RENDER_FILEPATH = 'output/$TIME-output.wav' # will create the file output/YYYY-MM-DD_hh-mm-ss-output.wav with the current time
CSOUND_CSD_FILEPATH (type=string/None, default=‘output/output.csd’) creates an output csd file for rendering the resulting concatenation with csound. See additional csound options here.
CSOUND_RENDER_FILEPATH (type=string/None, default=‘output/output.aiff’) sets the sound output file in the CSOUND_CSD_FILEPATH file. This is the name of csound’s output soundfile and will be created at the end of concatenation. See additional csound options here.
CSOUND_SCORE_FILEPATH (type=string/None, default=None) writes a simple textfile in the csound score format.
BACH_FILEPATH (type=string/None, default=‘output/bach_roll.txt’) Gathered syntax for concatenation selections that you can load into a bach.roll. See maxmsp/bach/main.maxpat for usage. See additional bach options here.
AAF_FILEPATH (type=string/None, default=None) Create an Advanced Authoring Format file for loading into Logic/Pro Tools. See additional aaf options here.
RPP_FILEPATH (type=string/None, default=None) Create a .rpp file for loading into Reaper. See additional Reaper options here.
HTML_LOG_FILEPATH (type=string/None, default=‘output/log.html’) a log file with lots of information from the concatenation algorithm.
COPY_OPTIONS_FILEPATH (type=string/None, default=None) Makes a copy of the options file that you're using so that you can remember how to recreate this output.
OUTPUT_LABEL_FILEPATH (type=string/None, default=‘output/outputlabels.txt’) Audacity-style labels showing the selected corpus sounds and how they overlap.
LISP_OUTPUT_FILEPATH (type=string/None, default=‘output/output.lisp.txt’) a textfile containing selected corpus events as a lisp-style list.
DICT_OUTPUT_FILEPATH (type=string/None, default=‘output/output.json’) a textfile containing selected corpus events in json format.
MAXMSP_OUTPUT_FILEPATH (type=string/None, default=‘output/output.maxmsp.json’) a textfile containing a list of selected corpus events. Data includes starttime in MS, duration in MS, filename, transposition, amplitude, etc.
TARGET_SEGMENT_LABELS_FILEPATH (type=string/None, default=‘output/targetlabels.txt’) Audacity-style labels showing how the target sound was segmented.
TARGET_SEGMENTATION_GRAPH_FILEPATH (type=string/None, default=None) like TARGET_SEGMENT_LABELS_FILEPATH, this variable creates a file to show information about target segmentation. Here however, the output is a jpg graph of the onset and offset times and the target’s power. This output requires you to install python’s module matplotlib.
TARGET_DESCRIPTORS_FILEPATH (type=string/None, default=None) saves the loaded target descriptors to a json dictionary.
TARGET_PLOT_DESCRIPTORS_FILEPATH (type=string/None, default=None) creates a plot of each target descriptor used in concatenation. Doesn’t create plots for averaged descriptors (“-seg”), only time varying descriptors.
DATA_FROM_SEGMENTATION_FILEPATH (type=string/None, default=None) This file lists all of the extra data of selected events during concatenation. This data is taken from corpus segmentation files, and includes everything after the startTime and endTime of each segment. This is useful if you want to tag each corpus segment with text based information for use later.
Csound Output
-> Watch a related discussion from the AudioGuide Tutorial.
AudioGuide concatenations are rendered with csound by default. The resulting audiofile is also played back at the command line by default.
CSOUND_CSD_FILEPATH (type=string/None, default=‘output/output.csd’) creates an output csd file for rendering the resulting concatenation with csound.
CSOUND_RENDER_FILEPATH (type=string/None, default=‘output/output.aiff’) sets the sound output file in the CSOUND_CSD_FILEPATH file. This is the name of csound’s output soundfile and will be created at the end of concatenation.
CSOUND_SCORE_FILEPATH (type=string/None, default=None) writes a simple textfile in the csound score format.
CSOUND_SR (type=int, default=48000) The sample rate used for csound rendering. Csound will interpolate the sample rates of all corpus files to this rate. It will be the sr of csound’s output soundfile.
CSOUND_BITS (type=int, default=16) The bitrate of the csound output soundfile. Valid values are 16, 24, and 32.
CSOUND_KSMPS (type=int, default=128) The ksmps value used for csound rendering. See csound’s documentation for more information.
CSOUND_NORMALIZE (type=bool, default=False) If True normalize csound's output soundfile after rendering.
CSOUND_NORMALIZE_PEAK_DB (type=float, default=-3) If CSOUND_NORMALIZE is True, normalization of this peak dB will take place.
CSOUND_PLAY_RENDERED_FILE (type=bool, default=True) if True, AudioGuide will play the rendered csound file at the command line at the end of the concatenative algorithm.
CSOUND_STRETCH_CORPUS_TO_TARGET_DUR (type=string/None, default=None) Affects the durations of concatenated sound events rendered by csound.
- None - Playback speed unchanged.
- pv - Uses a phase vocoder to stretch corpus sounds to match the duration of the corresponding target segments.
- transpose - Uses the speed of playback to change duration to match corresponding target segments. Note that, in this case, any other transposition information generated by the selection algorithm is overwritten (e.g. csf(pitchfilter=), csf(transmethod=).
CSOUND_CHANNEL_RENDER_METHOD (type=string, default=corpusmax) Tells AudioGuide how assign the channel of corpus segments in the csound output soundfile. The default is “corpusmax”.
- corpusmax - Creates an output soundfile with the same number of channels as the maxmimum of all corpus files (corpus files may have different channel counts).
- stereo - Mixes all corpus sounds into a 2-channel soundfile.
- targetoutputmix - Makes a simple stereo output where the target is in channel 1 and the corpus sounds are in channel 2.
- oneChannelPerVoice - Tells AudioGuide to put selected sounds from each item of the CORPUS list into a separate channel. The number of output channels will therefore equal the length of the CORPUS list variable.
- oneChannelPerOverlap - Tells AudioGuide to put overlapping selected sounds into different channels so that only one sound is happening in a given channel at any one time. The number of channels will be equal the maximum number of overlapping sounds in the concatenation.
- oneChannelPerInstrument - Tells AudioGuide to put selected sounds from each instrument into a separate channel. This only works when using INSTRUMENTS.
Logic/Pro Tools Output
-> Watch a related discussion from the AudioGuide Tutorial.
As of version 1.7, AudioGuide concatenations can be written to .aaf files and opened in Logic/Pro Tools. See examples/11-dawOutput.py
AAF_FILEPATH (type=string/None, default=None) Create an Advanced Authoring Format file for loading into Logic/Pro Tools.
AAF_INCLUDE_TARGET (type=bool, default=False) If True, adds the target soundfile to the Advanced Authoring Format output.
AAF_CPSTRACK_METHOD (type=string, default='cpsidx') A string specifying how to write selected corpus sounds into Advanced Authoring Format tracks. By default it is 'cpsidx'
- cpsidx - Puts corpus sounds into AAF tracks according to their idx in the CORPUS list and their channel count.
- minimum - Mixes all corpus sounds into a minimal number of AAF tracks.
AAF_AUTOLAUNCH (type=bool, default=False) If True, AudioGuide will automatically try to open the AAF file after it has been written. This is equivalent to double clicking the file in OSX.
Reaper Output
As of version 1.71, AudioGuide concatenations can be written to .rpp files and opened in reaper. Unlike the aaf output, reaper files capture csf() sound envelopes, csf(scaleDb), and corpus sound transpositions. See examples/11-dawOutput.py.
RPP_FILEPATH (type=string/None, default=None) Create a Reaper output file.
RPP_INCLUDE_TARGET (type=bool, default=False) If True, adds the target soundfile to the rpp file.
RPP_CPSTRACK_METHOD (type=string, default='cpsidx') A string specifying how to write selected corpus sounds to reaper tracks. By default it is 'cpsidx'
- cpsidx - Puts corpus sounds into RPP tracks according to their idx in the CORPUS list and their channel count.
- minimum - Mixes all corpus sounds into a minimal number of RPP tracks.
RPP_AUTOLAUNCH (type=bool, default=False) If True, AudioGuide will automatically try to open the RPP file after it has been written. This is equivalent to double clicking the file in OSX.
Bach Output
-> Watch a related discussion from the AudioGuide Tutorial.
Audioguide automatically creates an output file for every concatenation that may be loaded into a bach.roll in Max/MSP. The path for the bach output file, which is output/bach_roll.txt by default, is controlable by the BACH_FILEPATH variable. You may visualize, explore, and playback concatenated sounds with the patch maxmsp/bach/bach_playback.maxpat. You may also add descriptor data to Bach slots; see BACH_SLOTS_MAPPING below for details.
The options below give a few controls over how the output of a concatenation can be translated into a bach.roll input:
BACH_FILEPATH (type=string/None, default=‘output/bach_roll.txt’) Gathered syntax for concatenation selections that you can load into a bach.roll. See maxmsp/bach/main.maxpat for usage.
BACH_INCLUDE_TARGET (type=bool, default=True) if True, the target soundfile will be included as the first voice in bach_roll.txt.
BACH_DB_TO_VELOCITY_BREAKPOINTS (type=list of ints or floats, default=[-80, 0, -0, 127]) Breakpoint-style mapping of each target and corpus segment's loudness in dB into a velocity for the bach score. The default list will map linearly from -80 to 0dB onto 0 to 127 in midi velocity (sounds below -80dB will be clipped to velocity 0). Loudness in dB takes csf(scaleDb) into account. However you can specify additional breakpoints in pairs: e.g. [-80, 0, -60, 100, -0, 127].
BACH_TARGET_STAFF (type=string, default=F) The clef used for the target sound.
BACH_CORPUS_STAFF (type=string, default=FG) The clef used for corpus sounds.
Using Bach to Create Notated Scores
-> Watch a related discussion from the AudioGuide Tutorial.
AudioGuide's INSTRUMENTS infrastructure lets you restrict the way that elements of corpus can be used during concatenation to create playable instrument parts. These pays may be viewed, explored, and quantized with Bach in Max/MSP. INSTRUMENTS and its associated objects, score() and instr(), permit corpus resources to be deployed in time with a high degree of precision and customization, including the addition of articulation, noteneads, and restricting instrument behavior according to pitch, rhythm, and polyphony.
score() and instr()
The score() object is assigned to 'INSTRUMENTS' in the options file. score() consists of a list of instru() objects, each of which represents an instrument in the output score. instr()s are linked to cps() entries through their first argument, the instrTag string.score() may have multiple instr()s with the same instrTag; this indicates that there are more than one of a certain type of instrument in the ensemble that can use the same corpus resources.
As seen above with 'clef', the instr() object has keywords that affect the instrument's behavoir and how the instrument is translated into musical notation.
instr('instrTag', temporal_mode='sus', minspeed=0.075, interval_limit_breakpoints=[], interval_limit_range_per_sec=None, polyphony_max_voices=1, polyphony_max_range=None, polyphony_min_range=None, polyphony_permit_unison=False, polyphony_max_db_difference=4, technique_switch_delay_map=[], clef='G', key='CM'))
- instrTag - This instrument's instrTag. Any corpus entries with the same string will be associated with this instrument.
- temporal_mode - 'sus' by default, which indicates a sustained event.
- minspeed - The minimum distance between adjecent note onsets for this instrument in seconds.
- interval_limit_breakpoints - A list. Described in the Handling Time second, below.
- interval_limit_range_per_sec - None or a number. Described in the Handling Time second, below.
- polyphony_max_voices - Maximum voices that may be picked at the same time for this instrument.
- polyphony_max_range - If a number, the maximum interval from the lowest to highest note in a chord in semitones. If None, there is no limit.
- polyphony_min_range - If a number, the minimum interval from the lowest to highest note in a chord in semitones. If None, there is no limit.
- polyphony_permit_unison - If True, unisons may be selected as part of a chord.
- polyphony_minspeed - The minimum allowable time between polyphonic chord onsets in seconds. This works the same way as minspeed, but only applies to polyphonic selections.
- technique_switch_delay_map* - If different techniques are specified in various corpus csf(instrParams={})s, the technique_switch_delay_map let's you specify a list of minimum delay times needed to switich form one technique to another. ['tech1', 'tech2', 0.5] = to go from tech1 to tech2, there must be a delay of at least 0.5 seconds.
- clef* - The clef for this instrument in the bach.roll. Valid values include, 'F', 'G', 'Alto', and 'FG' for a grand staff. See bach's documentation on clefs for more information.
- key* - The key for this instrument in the bach.roll. See bach's documentation on keys for more information.
Almost all keyword arguments may be overridden in individual csf()s through the csf(instrParams={}) dictionary (those which may not be are denoted with an asterisk). In the example below, the arco violin notes have a 0.05 second minspeed and may have 2 voice polyphony. However the pizzicato sounds have a minspeed of 0.2 second and will always be monophonic:
The csf(instrParams={}) dictionary also permits providing information about articulation, noteheads, and text annotation in the output score for individual csf() entries:
Handling Pitch
The pitches that make it into the bach.roll come from selected corpus segment's MIDIPitch. You can change how midi pitch is evalutated with the csf(midiPitchMethod) keyword. By default, it is 'composite', which first searches for a midi pitch written into the filename of each corpus sound. If no pitch is found, midi pitch is taken from f0-seg. Generally, it is best to use sample databases with pitches in the filenames, as f0-seg is not very reliable. For unpitched sounds, or databases without pitches written into the filenames, you can customize the pitch data by picking a different csf(midiPitchMethod).
There are several nuanced controls for specifying how pitch may move over time. Consider, first, the unrestricted pitch selection of a solo violin concatenation:

interval_limit_breakpoints lets the user specify a list of breakpoints for how intervals are restricted over time. In the example below, the breakpoints are given as [(0,7), (1, 24)], which translates to: if the distance between this selection and the end of the last note is 0 second, restrict this intervals choice to 7 semitones. if the distance is 1 second, restrict it to 24 semitones. The algorithm interpolates these breakpoints, so if the distance in seconds is 0.5, the restriction interval will be 15.5 semitones. You must have at least 2 breakpoints, and the first time difference must be zero, but you have have additional breakpoints if you want. Any note distances greater than the biggest time difference found in interval_limit_breakpoints (in this example, 1 second), any interval is possible. This also works for polyphony.

interval_limit_range_per_sec restricts what pitches may be selected for an instrument by limiting the total range of pitch for any given second to a number of semitones. Below, the violin is restricted to a 3 semitones total range for any one second slice of it's part. This also works for polyphony.

Handling Dynamics/Volume
Audioguide puts two different kinds of dynamic information into the bachroll.
The first is in each note's midi velocity. Here, audioguide gives a note's playback volume such so that soundfiles in the bach score can be played back at the same volume heard in audioguide's soundfile output. This value comes from each csf(scaleDb). This means that if you use scaleDb='filenamedyn', you will get the same amplitude scalars in bach's velocity as you audioguide uses internally. This value is dB is also included in slot 13 (see below).
The second set of information is found in the written dynamic values (e.g. f, mp), put into bach's dynamic slot (ag uses the default slot, 20). These strings are obtained, by default, through any dynamics found in the filenames of the samples that are used. For instance, if audioguide picks the sound 'HA_ES_mu_mf_C4.wav', it will automatically be assigned a written dynamic of mf in slot 20. However, if you're using soundfiles in a csf() that do not have dynamics written into the filenames, audioguide will automatically assign each sf in a csf() a dynamic according to the relative loudness of each sf. These loudnesses get mapped onto a list of dynamics which, by default, are ['pp', 'p', 'mp', 'mf', 'f', 'ff']. However this can be changed for individual csf()s:
Handling Time
Audioguide provides methods in the instruments interface for controlling how instr()s behave in time.
minspeed and polyphony_minspeed are the most basic, brute-force controls, dictating the minimum time in seconds between sucessive onsets for an instrument.
instr(temporal_mode) is very important to telling audioguide how to treat selected events for an instrument with regard to minspeed and polyphony_minspeed. If instr(temporal_mode='sus'), all selected corpus sounds will be treated as sustained events, and minspeed will be restricted by the start time and stop time of a selected note. If instr(temporal_mode='artic'), all selected corpus sounds will be treated as duration-less, and minspeed will only use a note's start time to restrict density.
instr(technique_switch_delay_map) let's you specify a minimum delay time between changing from one type of corpus resources to another.
Slot Data
Data from the concatenative process is automatically added to the BACH_FILEPATH textfile and can be accessed via Bach's slots infrastructure. The table below summarizes the data that AudioGuide puts into different Bach slots by default.| Keyword | Default Bach Slot Number | Description | Valid For |
|---|---|---|---|
| fullpath | 1 | This note's full path. | Target and Corpus |
| sfskiptime | 2 | This note's filename's skip time in the file in milliseconds. | Target and Corpus |
| sfchannels | 3 | This note's filename's number of channels | Target and Corpus |
| env | 4 | This note's amplitude envelope as a bach function. Combines csf(scaleDb), csf(onsetLen), and csf(offsetLen) | Target and Corpus |
| transposition | 5 | This note's corresponding transposition from the concatenative process in semitones. | Target and Corpus |
| selectionnumber | 6 | For the corpus: this note's selection number in the concatenative process. If 0, it was the first sound picked for the target segment in question. For a target segment: the total number of sounds selected. | Target and Corpus |
| instr_dynamic | 20 | This chord/note's dynamics. By default, these are taken from the filename of the selected sounds (C4-mf-IV.wav will have a dynamic of mf) | Corpus with InstrTag |
| instr_articulation | 22 | This note/chord's articulation taken from the csf(instrParams) dictionary, e.g. csf(instrParams={'articulation': 'staccato'}) | Corpus with InstrTag |
| instr_notehead | 23 | This note/chord's notehead taken from the csf(instrParams) dictionary, e.g. csf(instrParams={'notehead': 'cross'}) | Corpus with InstrTag |
| instr_annotation | 24 | this note/chord's annotation text taken from the csf(instrParams) dictionary, e.g. csf(instrParams={'annotation': 'strike_with_hand'}) | Corpus with InstrTag |
| instr_technique | 25 | This csf()'s technique string from the csf(instrParams) dictionary, e.g. csf(instrParams={'technique': 'pizz'}) | Corpus with InstrTag |
| instr_temporal_mode | 26 | This csf()'s temporal_mode from the csf(instrParams) dictionary, e.g' csf(instrParams={'temporal_mode': 'artic'}) | Corpus with InstrTag |
# custom slot assignment:
BACH_SLOTS_MAPPING = {1: 'instr_technique', 2: 'fullpath', 3: 'sfskiptime', 10: 'noisiness-seg', 11: 'centroid'}
# this will put each selected sound with an instr's technique, fullpath, and skip time into slots 1-3. Each selected sound's averaged noisiness will be put into slot 10 (as a float) and its time-varying centroid in slot 11 (as a floatlist).
Other Options
Descriptor Computation Parameters
DESCRIPTOR_FORCE_ANALYSIS (type=bool, default=False) if True, AudioGuide is forced to remake all analysis file, even if previously made.
DESCRIPTOR_WIN_SIZE_SEC (type=float, default=0.04096) the FFT window size of descriptor analysis in seconds. Note that this value gets automatically rounded to the nearest power-of-two size based on IRCAMDESCRIPTOR_RESAMPLE_RATE. 0.04096 seconds = 512 @ 12.5kHz (the default resample rate).
DESCRIPTOR_HOP_SIZE_SEC (type=float, default=0.01024) the FFT window overlaps of descriptor analysis in seconds. Note that this value gets automatically rounded to the nearest power-of-two size based on IRCAMDESCRIPTOR_RESAMPLE_RATE. Important, as it effectively sets of temporal resolution of AudioGuide. Performance is best when DESCRIPTOR_HOP_SIZE_SEC/DESCRIPTOR_WIN_SIZE_SEC is a whole number.
IRCAMDESCRIPTOR_RESAMPLE_RATE (type=int, default=12500) The internal resample rate of the IRCAM analysis binary. Important, as it sets the frequency resolution of spectral sound descriptors.
IRCAMDESCRIPTOR_WINDOW_TYPE (type=string, default=‘blackman’) see ircamdescriptor documentation for details.
IRCAMDESCRIPTOR_NUMB_MFCCS (type=int, default=13) sets the number of MFCCs to make. When you use the descriptor 'mfccs' if will automatcially be expanded into mfccs1-N where N is IRCAMDESCRIPTOR_NUMB_MFCCS.
IRCAMDESCRIPTOR_F0_MAX_ANALYSIS_FREQ (type=float, default=5000) see ircamdescriptor documentation for details.
IRCAMDESCRIPTOR_F0_MIN_FREQUENCY (type=float, default=20) minimum possible f0 frequency.
IRCAMDESCRIPTOR_F0_MAX_FREQUENCY (type=float, default=5000) maximum possible f0 frequency.
IRCAMDESCRIPTOR_F0_AMP_THRESHOLD (type=float, default=1) Thresholding of the spectrum in F0 detection.
DESCRIPTOR_DATABASE_SIZE_LIMIT (type=float, default=1) The maximum size of the analysis database in gigabytes (audioguide/data) that will trigger AudioGuide to delete the oldest analysis files.
DESCRIPTOR_DATABASE_AGE_LIMIT (type=float, default=7) The minimum age in days of analysis files in the analysis database (audioguide/data) that AudioGuide will delete if the size of the database is over DESCRIPTOR_DATABASE_SIZE_LIMIT gb.
Concatenation
ROTATE_VOICES (type=bool, default=False]) if True, AudioGuide will rotate through the list of corpus entries during concatenation. This means that, when selecting corpus segment one, AudioGuide will only search sound segments from the first item of the CORPUS variable. Selection 2 will only search the second, and so on. Corpus rotation is modular around the length of the CORPUS variable. If the corpus only has one item, True will have no effect.
VOICE_PATTERN (type=list, default=[]) if an empty list, this does nothing. However, if the user gives a list of strings, AudioGuide will rotate through this list of each concatenative selection and only use corpus segments who’s filepath match this string. Matching can use parts of the filename, not necessarily the whole path and it is not case sensitive.
DYNAMIC_TO_DECIBEL (type=dict, default={'pp': -50, 'p': -40, 'mp': -34, 'mf': -24, 'f': -20, 'ff': -10}) This variable specifies the default decebel values for dynamic strings used by csf(scaleDb='filenamedyn').
FILENAMESTRING_TO_DYNAMICS (type=dict, default={}) User-defined strings for matching soundfile names with dynamics as in DYNAMIC_TO_DECIBEL. E.g. {'really loud': 'ff', 'loudish': 'f'}. Any filenames which match one these partial strings will be assigned the given dynamic, and then the decebel scalar found in DYNAMIC_TO_DECIBEL will be used if scaleDb='filenamedyn'.
OUTPUT_GAIN_DB (type=int/None, default=None) adds a uniform gain in dB to all selected corpus units. Affects the subtractive envelope calculations and descriptor mixtures as well as csound rendering.
RANDOM_SEED (type=int/None, default=None) sets the pseudo-random seed for random unit selection. By default a value of None will use the system’s timestamp. Setting an integer will create repeatable random results.
Post-Concatenation Event Manipulation
These options change selected corpus events after concatenative selection, meaning that they do not affect similarity calculations, but are applied afterwards. At the moment, all of these parameters affect the temporality of the corpus sounds. These parameters affect all output files - csound, midi, json, etc.
OUTPUTEVENT_ALIGN_PEAKS (type=bool, default=False) If True aligns the peak times of corpus segments to match those of the target segments. Thus, every corpus segment selected to represent a target segment will be moved in time such that corpus segment's peak amplitude is aligned with the target segment's.
OUTPUTEVENT_QUANTIZE_TIME_METHOD (type=string/None, default=None) controls the quantisation of the start times of events selected during concatenation. Note that any quantisation takes place after the application of OUTPUTEVENT_TIME_STRETCH and OUTPUTEVENT_TIME_ADD, as detailed below. This variable has the following possible settings:
- None - no quantisation takes place (the default).
- ‘snapToGrid’ - conform the start times of events to a grid spaced in OUTPUTEVENT_QUANTIZE_TIME_INTERVAL second slices.
- ‘medianAggregate’ - change each event’s start time to the median start time of events in slices of OUTPUTEVENT_QUANTIZE_TIME_INTERVAL seconds.
OUTPUTEVENT_QUANTIZE_TIME_INTERVAL (type=float, default=0.25) defines the temporal interval in seconds for quantisation. If OUTPUTEVENT_QUANTIZE_TIME_METHOD = None, this doesn’t do anything.
OUTPUTEVENT_TIME_STRETCH (type=float, default=1.) stretch the temporality of selected units. A value of 2 will stretch all events offsets by a factor of 2. Does not affect corpus segment durations.
OUTPUTEVENT_TIME_ADD (type=float, default=0.) offset the start time of selected events by a value in seconds.
OUTPUTEVENT_DURATION_SELECT (type=string, default=cps) if 'cps', AudioGuide will play each selected corpus sample according to its duration. if 'tgt', AudioGuide will use the duration of the target segment a corpus segment was matched to to determine its playback duration. 'tgt' may result in clipped corpus sounds.
OUTPUTEVENT_DURATION_MIN (type=float/None, default=None) Sets a minimum duration for all selected corpus segments. When this variable is a float, the length of each segment's playback will be at least OUTPUTEVENT_DURATION_MIN seconds (unless the soundfile is too short, in which case the duration will be the soundfile's duration). If None is given (the default), no minimum duration is enforced.
OUTPUTEVENT_DURATION_MAX (type=float/None, default=None) Sets a maximum duration for all selected corpus segments. When this variable is a float, the length of each segment's playback cannot be more than OUTPUTEVENT_DURATION_MAX seconds. If None is given (the default), no maximum duration is enforced.
Printing/Interaction
SEARCH_PATHS (type=list, default=[]) a list of strings, each of which is a path to a directory where soundfile are located. These paths extend the list of search paths that AudioGuide examines when searching for target and corpus soundfiles. The default is an empty list, which doesn’t do anything.
VERBOSITY (type=int, default=2) affects the amount of information AudioGuide prints to the terminal. A value of 0 yields nothing. A value of 1 prints a minimal amount of information. A value of 2 (the default) prints refreshing progress bars to indicate the progress of the algorithms.
PRINT_SELECTION_HISTO (type=bool, default=False) if True will print robust information about corpus selection after concatenation. If false (the default) will add this information to the log file, if used.
PRINT_SIM_SELECTION_HISTO (type=bool, default=False) if True will print robust information about corpus overlapping selection after concatenation. If false (the default) will add this information to the log file, if used.
Descriptor Retrieval with agGetSfDescriptors.py
agGetSfDescriptors.py is a simple script that exports continuous descriptor values of a soundfile. The output format is a json dictionary. To use it simply call the script with the soundfile as the first argument and the output path as the second argument.
python agGetSfDescriptors.py examples/lachenmann.aiff examples/lachenmann.json
Appendix 1 - Descriptors
The tables below lists all descriptors available in AudioGuide.| Descriptor Description | AudioGuide Averaged Descriptor | AudioGuide Time Varying Descriptor |
|---|---|---|
| duration | dur-seg | |
| effective duration | effDur-seg1 | |
| peak amplitude in frames | peakTime-seg | |
| log attack time in seconds | logAttackTime-seg | |
| time in file in percent | percentInFile-seg | |
| midi pitch from filename | MIDIPitch-seg2 | |
| amplitude | power-seg, power-mean-seg3 | power |
| spectral centroid | centroid-seg | centroid |
| combination of 4 spectral crest descriptors | crests-seg | crests |
| spectral crest coefficient 1 ... 4 | crest0-seg ... crest3-seg | crest0 ... crest3 |
| spectral decrease | decrease-seg | decrease |
| combination of 4 spectral flatness descriptors | flatnesses-seg | flatnesses |
| spectral flatness coefficient 1 ... 4 | flatness0-seg ... flatness3-seg | flatness0 ... flatness3 |
| spectral kurtosis | kurtosis-seg | kurtosis |
| spectral noisiness | noisiness-seg | noisiness |
| spectral rolloff | rolloff-seg | rolloff |
| spectral sharpness | sharpness-seg | sharpness |
| spectral skewness | skewness-seg | skewness |
| spectral slope | slope-seg | slope |
| spectral spread | spread-seg | spread |
| spectral variation | variation-seg | variation |
| fundamental frequency | f0-seg4 | f0 |
| zero crossings | zeroCross-seg | zeroCross |
| combination of 12 mel frequency cepstral coefficients | mfccs-seg | mfccs |
| mel frequency cepstral coefficient 1 ... 12 | mfcc1-seg ... mfcc12-seg | mfcc1 ... mfcc12 |
| combination of 12 chroma descriptors | chromas-seg | chromas |
| chroma 1 ... 12 | chroma0-seg ... chroma11-seg | chroma0 ... chroma11 |
| harmonic spectral centroid | harmoniccentroid-seg | harmoniccentroid |
| harmonic spectral decrease | harmonicdecrease-seg | harmonicdecrease |
| harmonic spectral deviation | harmonicdeviation-seg | harmonicdeviation |
| harmonic spectral kurtosis | harmonickurtosis-seg | harmonickurtosis |
| harmonic spectral odd-even ratio | harmonicoddevenratio-seg | harmonicoddevenratio |
| harmonic spectral rolloff | harmonicrolloff-seg | harmonicrolloff |
| harmonic spectral skewness | harmonicskewness-seg | harmonicskewness |
| harmonic spectral slope | harmonicslope-seg | harmonicslope |
| harmonic spectral spread | harmonicspread-seg | harmonicspread |
| harmonic spectral tristimulus coefficient 1 | harmonictristimulus0-seg | harmonictristimulus0 |
| harmonic spectral tristimulus coefficient 2 | harmonictristimulus1-seg | harmonictristimulus1 |
| harmonic spectral tristimulus coefficient 3 | harmonictristimulus2-seg | harmonictristimulus2 |
| harmonic spectral variation | harmonicvariation-seg | harmonicvariation |
| perceptual spectral centroid | perceptualcentroid-seg | perceptualcentroid |
| perceptual spectral decrease | perceptualdecrease-seg | perceptualdecrease |
| perceptual spectral deviation | perceptualdeviation-seg | perceptualdeviation |
| perceptual spectral kurtosis | perceptualkurtosis-seg | perceptualkurtosis |
| perceptual spectral odd-even ratio | perceptualoddtoevenratio-seg | perceptualoddtoevenratio |
| perceptual spectral rolloff | perceptualrolloff-seg | perceptualrolloff |
| perceptual spectral skewness | perceptualskewness-seg | perceptualskewness |
| perceptual spectral slope | perceptualslope-seg | perceptualslope |
| perceptual spectral spread | perceptualspread-seg | perceptualspread |
| perceptual spectral tristimulus coefficient 1 | perceptualtristimulus0-seg | perceptualtristimulus0 |
| perceptual spectral tristimulus coefficient 2 | perceptualtristimulus1-seg | perceptualtristimulus1 |
| perceptual spectral tristimulus coefficient 3 | perceptualtristimulus2-seg | perceptualtristimulus2 |
| perceptual spectral variation | perceptualvariation-seg | perceptualvariation |
1. effDur-seg ignores silences whereas dur-seg does not
2. myfileC4.wav=60, basooonFs2.wav=42, HA_ES_mu_Ab6_p.wav=92, etc.
3. power-seg is a segment's peak amplitude. power-mean-seg is the average of the segment.
4. f0-seg is the median f0, not a power weighted average. Thus f0-seg will be a pitch actually present in the f0 time varying array.
Also note that any time varying descriptor can take a few different text string modifiers which come at the end of the descriptor string.
| Descriptor append string | Effect | Example |
|---|---|---|
| -delta | First order difference of the time varying series | centroid-delta = the first order difference of time varying centroids |
| -delta-seg | Average of the first order difference of the time varying series | centroid-delta-seg = a power-weighted average of the first order difference of time varying centroids |
| -deltadelta | Second order difference of the time varying series | power-deltadelta = the second order difference of time varying powers |
| -deltadelta-seg | Average of the second order difference of the time varying series | zeroCross-deltadelta-seg = a power-weighted average of the second order difference of time varying zero crossings |
| -slope-seg | Slope regression of the timevarying series | power-slope-seg = a linear regression descripbing the slope of the time varying series of powers |
| -minseg | Minimum of the timevarying series | centroid-minseg = minimum of the time varying series of centroids |
| -maxseg | Maximum of the timevarying series | centroid-maxseg = maximum of the time varying series of centroids |
| -stdseg | Standard deviation of the timevarying series | centroid-stdseg = standard deviation of the time varying series of centroids |
| -kurtseg | Kurtosis of the timevarying series | centroid-kurtseg = kurtosis of the time varying series of centroids. Uses scipy.stats.kurtosis |
| -skewseg | Skewness of the timevarying series | centroid-skewseg = skewness of the time varying series of centroids. Uses scipy.stats.skew |
| -stats | Statistics on the timevarying series | centroid-stats = a equally-weighted combination of centroid-seg, centroid-minseg, centroid-maxseg, centroid-stdseg, centroid-kurtseg, centroid-skewseg |
The SEARCH from the exampe below first takes the best 20% of corpus matches according to a linear regression of each segments amplitude. Of the remaining 20% a segment is chosen based on a combination of the averaged first order different of f0 and the second order time varying centroids.